
Beroende och oberoende slumpmässiga händelser. Grundformler för addition och multiplikation av sannolikheter

Beroende och oberoende slumpmässiga händelser.
Grundformler för addition och multiplikation av sannolikheter
Begreppen beroende och oberoende av slumpmässiga händelser. Villkorlig sannolikhet. Formler för addition och multiplikation av sannolikheter för beroende och oberoende slumpmässiga händelser. Total sannolikhetsformel och Bayes formel.
Additionssatser
Låt oss hitta sannolikheten för summan av händelser och (under antagandet om deras kompatibilitet eller inkonsekvens).
Sats 2.1. Sannolikheten för summan av ett ändligt antal inkompatibla händelser är lika med summan av deras sannolikheter:
Exempel 1 Sannolikheten att ett par herrskor i storlek 44 kommer att säljas i butik är 0,12; 45:e - 0,04; 46:a och mer - 0,01. Hitta sannolikheten att ett par herrskor i minst storlek 44 kommer att säljas.
Beslut. Det önskade eventet inträffar om ett par skor i storlek 44 ( event ) eller storlek 45 ( event ), eller åtminstone storlek 46 ( event ) säljs, dvs eventet är summan av event . Händelserna och är oförenliga. Därför får vi enligt satsen om summan av sannolikheter
Exempel 2 Under villkoren i exempel 1, hitta sannolikheten för att nästa par skor mindre än storlek 44 kommer att säljas.
Beslut. Evenemangen "ett par skor mindre än storlek 44 kommer att säljas" och "ett par skor i storlek inte mindre än storlek 44 kommer att säljas" är motsatta. Därför, enligt formel (1.2), sannolikheten för att den önskade händelsen inträffar
eftersom , som finns i exempel 1.
Sats 2.1 om addition av sannolikheter är endast giltig för inkompatibla händelser. Att använda det för att hitta sannolikheten för gemensamma händelser kan leda till felaktiga och ibland absurda slutsatser, vilket tydligt syns i följande exempel. Låt Electra Ltd fullfölja ordern i tid med en sannolikhet på 0,7. Vad är sannolikheten att företaget kommer att slutföra minst en av tre beställningar i tid? De händelser som består i att bolaget kommer att fullgöra den första, andra, tredje ordern i tid kommer att betecknas. Om vi tillämpar sats 2.1 om tillägg av sannolikheter för att hitta den önskade sannolikheten, så får vi . Sannolikheten för händelsen visade sig vara större än en, vilket är omöjligt. Detta eftersom evenemangen är gemensamma. Uppfyllelsen av den första beställningen i tid utesluter faktiskt inte att de andra två beställningarna fullföljs i tid.
Låt oss formulera en sannolikhetsadditionssats i fallet med två gemensamma händelser (sannolikheten för att deras gemensamma inträffar kommer att beaktas).
Sats 2.2. Sannolikheten för summan av två gemensamma händelser är lika med summan av sannolikheterna för dessa två händelser utan sannolikheten för att de ska inträffa tillsammans:
Beroende och oberoende evenemang. Villkorlig sannolikhet
Skilj mellan beroende och oberoende händelser. Två händelser sägs vara oberoende om förekomsten av en av dem inte ändrar sannolikheten för att den andra inträffar. Till exempel, om två automatiska linjer fungerar i en verkstad, som inte är sammankopplade enligt produktionsförhållandena, är stopp för dessa linjer oberoende händelser.
Exempel 3 Myntet vänds två gånger. Sannolikheten för att "vapenskölden" ska uppträda i det första testet (händelse ) beror inte på utseendet eller avsaknaden av "vapnet" i det andra testet (händelse ). I sin tur beror sannolikheten för utseendet av "vapnet" i det andra testet inte på resultatet av det första testet. Således händelser och oberoende.
Flera evenemang kallas kollektivt oberoende, om någon av dem inte beror på någon annan händelse och på någon kombination av de andra.
Händelserna kallas beroende, om en av dem påverkar sannolikheten att den andra inträffar. Till exempel är två produktionsanläggningar sammankopplade av en enda teknisk cykel. Då beror sannolikheten för misslyckande för en av dem på den andras tillstånd. Sannolikheten för en händelse, beräknad med antagande av att en annan händelse inträffar, kallas betingad sannolikhet händelser och betecknas med .
Villkoret för oberoende av en händelse från en händelse skrivs i formen, och villkoret för dess beroende - i formen. Betrakta ett exempel på att beräkna den villkorade sannolikheten för en händelse.
Exempel 4 Det finns 5 framtänder i kartongen: två slitna och tre nya. Två på varandra följande utdragningar av framtänder görs. Bestäm den villkorade sannolikheten för utseendet av en sliten fräs under den andra extraktionen, förutsatt att fräsen som togs bort för första gången inte återförs till lådan.
Beslut. Låt oss beteckna utvinningen av en sliten fräs i det första fallet, och - utvinningen av en ny. Sedan . Eftersom den borttagna fräsen inte återförs till lådan ändras förhållandet mellan antalet slitna och nya fräsar. Därför beror sannolikheten för att ta bort en sliten fräs i det andra fallet på vilken händelse som ägde rum innan.
Låt oss beteckna den händelse som innebär utdragning av den slitna fräsen i det andra fallet. Sannolikheterna för denna händelse är:
Därför beror sannolikheten för en händelse på om händelsen inträffade eller inte.
Sannolikhetsmultiplikationsformler
Låt händelserna och vara oberoende, och sannolikheterna för dessa händelser är kända. Hitta sannolikheten för att kombinera händelser och .
Sats 2.3. Sannolikheten för en gemensam förekomst av två oberoende händelser är lika med produkten av sannolikheterna för dessa händelser:
Följd 2.1. Sannolikheten för en gemensam förekomst av flera händelser som är oberoende i aggregatet är lika med produkten av sannolikheterna för dessa händelser:
Exempel 5 Tre lådor innehåller 10 stycken vardera. I den första lådan - 8 standarddelar, i den andra - 7, i den tredje - 9. En del tas ut slumpmässigt från varje låda. Hitta sannolikheten att alla tre delarna som tas ut är standard.
Beslut. Sannolikheten att en standarddel (händelse ) tas från den första rutan, . Sannolikheten att en standarddel (händelse ) tas från den andra rutan, . Sannolikheten att en standarddel (händelse ) tas från den tredje rutan, . Eftersom händelserna , och är oberoende i aggregatet, är den önskade sannolikheten (enligt multiplikationssatsen)
Låt händelserna och vara beroende, och sannolikheterna och vara kända. Låt oss hitta sannolikheten för produkten av dessa händelser, det vill säga sannolikheten att både händelsen och händelsen kommer att dyka upp.
Sats 2.4. Sannolikheten för den gemensamma förekomsten av två beroende händelser är lika med produkten av sannolikheten för en av dem med den villkorliga sannolikheten för den andra, beräknad under antagandet att den första händelsen redan har inträffat:
Följd 2.2. Sannolikheten för den gemensamma förekomsten av flera beroende händelser är lika med produkten av sannolikheten för en av dem med de villkorade sannolikheterna för alla de andra, och sannolikheten för varje efterföljande händelse beräknas på antagandet att alla tidigare händelser redan har dykt upp .
Exempel 6 En urna innehåller 5 vita kulor, 4 svarta och 3 blå. Varje försök består av att dra en boll slumpmässigt utan att returnera den till urnan. Hitta sannolikheten att vid det första testet kommer en vit boll att dyka upp (händelse ), vid den andra - svart (händelse ) och vid den tredje - blå (händelse ).
Beslut. Sannolikheten för att en vit boll dyker upp vid första försöket. Sannolikheten för att en svart boll dyker upp i det andra försöket, beräknat under antagande att en vit boll dök upp i det första försöket, det vill säga den villkorade sannolikheten . Sannolikheten för att en blå boll skulle dyka upp i det tredje försöket, beräknat under antagande att en vit boll dök upp i det första försöket och en svart i det andra försöket, . Önskad sannolikhet
Total sannolikhetsformel
Sats 2.5. Om en händelse inträffar endast om en av händelserna inträffar, och bildar en komplett grupp av inkompatibla händelser, är sannolikheten för händelsen lika med summan av produkterna av sannolikheterna för var och en av händelserna med motsvarande villkorade sannolikhet för händelsen :
I det här fallet kallas händelserna hypoteser, och sannolikheterna kallas a priori. Denna formel kallas den totala sannolikhetsformeln.
Exempel 7 Monteringslinjen tar emot delar från tre maskiner. Maskinens prestanda är inte densamma. På den första maskinen produceras 50% av alla delar, på den andra - 30%, på den tredje - 20%. Sannolikheten för en kvalitetsmontering vid användning av en del tillverkad på den första, andra respektive tredje maskinen är 0,98, 0,95 och 0,8. Bestäm sannolikheten för att monteringen som kommer av transportören är av hög kvalitet.
Beslut. Låt oss utse en händelse som betyder lämpligheten för den sammansatta noden; , och - händelser som betyder att delarna är gjorda på den första, andra och tredje maskinen. Sedan
Önskad sannolikhet
Bayes formel
Denna formel används för att lösa praktiska problem när en händelse som dyker upp tillsammans med någon av händelserna som bildar en komplett grupp av händelser har inträffat och en kvantitativ omvärdering av hypotesernas sannolikheter krävs. A priori (före erfarenhet) sannolikheter är kända. Det är nödvändigt att beräkna a posteriori (efter erfarenhet) sannolikheter, det vill säga i huvudsak är det nödvändigt att hitta villkorade sannolikheter. För en hypotes ser Bayes formel ut så här.
Sannolikhetsdefinitioner
Klassisk definition
Den klassiska "definitionen" av sannolikhet kommer från begreppet lika möjligheter som en objektiv egenskap hos de fenomen som studeras. Ekvivalens är ett odefinierbart begrepp och etableras utifrån allmänna överväganden om symmetrin hos de fenomen som studeras. Till exempel, när man kastar ett mynt, antas det att det, på grund av myntets förmodade symmetri, materialets homogenitet och slumpmässigheten (icke-bias) i kastningen, det inte finns någon anledning att föredra "svansar" framför "örnar" eller vice versa, det vill säga att förlusten av dessa sidor kan anses vara lika sannolik (equiprobable) .
Tillsammans med begreppet ekvisannolikhet i det allmänna fallet kräver den klassiska definitionen också begreppet en elementär händelse (utfall) som gynnar eller inte gynnar händelsen A. Vi talar om utfall, vars förekomst utesluter möjligheten av förekomsten av andra utfall. Dessa är oförenliga elementära händelser. Till exempel, när en tärning kastas, kommer ett visst nummer att elimineras från de andra numren.
Den klassiska definitionen av sannolikhet kan formuleras på följande sätt:
Sannolikheten för en slumpmässig händelse A kallas förhållandet mellan talet n oförenliga lika sannolika elementära händelser som utgör händelsen A , till antalet alla möjliga elementära händelser N :
Anta till exempel att två tärningar kastas. Det totala antalet lika möjliga utfall (elementära händelser) är uppenbarligen 36 (6 möjligheter på varje tärning). Uppskatta sannolikheten att få 7 poäng. Att få 7 poäng är möjligt på följande sätt: 1+6, 2+5, 3+4, 4+3, 5+2, 6+1. Det vill säga, det finns bara 6 lika sannolika utfall som gynnar händelse A - att få 7 poäng. Därför blir sannolikheten lika med 6/36=1/6. Som jämförelse är sannolikheten att få 12 poäng eller 2 poäng bara 1/36 - 6 gånger mindre.
Geometrisk definition
Trots att den klassiska definitionen är intuitiv och härledd från praktiken, kan den åtminstone inte tillämpas direkt om antalet lika möjliga utfall är oändligt. Ett slående exempel på ett oändligt antal möjliga utfall är ett begränsat geometriskt område G, till exempel på ett plan, med en area S. En slumpmässigt "kastad" "punkt" med lika sannolikhet kan vara var som helst i denna region. Problemet är att bestämma sannolikheten för att en punkt hamnar i någon underdomän g med area s. I det här fallet, genom att generalisera den klassiska definitionen, kan vi komma till en geometrisk definition av sannolikheten att falla in i underdomänen:
Med tanke på den lika möjligheten beror denna sannolikhet inte på formen av regionen g, den beror bara på dess yta. Denna definition kan naturligtvis generaliseras till ett utrymme av vilken dimension som helst, där begreppet "volym" används istället för area. Dessutom är det denna definition som leder till den moderna axiomatiska definitionen av sannolikhet. Begreppet volym generaliseras till begreppet ett "mått" av någon abstrakt uppsättning, till vilket kraven ställs, vilket "volymen" också har i den geometriska tolkningen - för det första är dessa icke-negativitet och additivitet.
Frekvens (statistisk) bestämning
Den klassiska definitionen stöter på svårigheter av oöverstiglig natur när man överväger komplexa problem. I synnerhet kan det i vissa fall inte vara möjligt att identifiera lika sannolika fall. Även i fallet med ett mynt finns det som bekant en helt klart inte lika sannolik möjlighet att en "kant" faller ut, vilket inte kan uppskattas utifrån teoretiska överväganden (man kan bara säga att det är osannolikt, och detta är snarare praktisk). Därför, vid gryningen av bildandet av sannolikhetsteorin, föreslogs en alternativ "frekvens" definition av sannolikhet. Formellt kan nämligen sannolikheten definieras som gränsen för frekvensen av observationer av händelse A, förutsatt att observationerna är homogena (det vill säga likheten mellan alla observationsförhållanden) och deras oberoende av varandra:
![]()
var är antalet observationer och är antalet förekomster av händelsen.
Trots att denna definition snarare pekar på ett sätt att uppskatta en okänd sannolikhet - med hjälp av ett stort antal homogena och oberoende observationer - så speglar denna definition ändå innehållet i sannolikhetsbegreppet. Nämligen, om en viss sannolikhet tillskrivs en händelse, som ett objektivt mått på dess möjlighet, så betyder detta att vi under fasta förhållanden och flera upprepningar bör få en frekvens av dess förekomst nära (ju närmare, desto fler observationer). Egentligen är detta den ursprungliga innebörden av begreppet sannolikhet. Den bygger på en objektivistisk syn på naturfenomen. Nedan kommer vi att överväga de så kallade lagarna för stora tal, som ger en teoretisk grund (inom ramen för det moderna axiomatiska tillvägagångssättet som presenteras nedan), inklusive för frekvensuppskattning av sannolikhet.
Axiomatisk definition
I det moderna matematiska tillvägagångssättet ges sannolikheten av Kolmogorovs axiomatik. Det antas att vissa utrymme för elementära händelser. Delmängder av detta utrymme tolkas som slumpmässiga händelser. Unionen (summan) av vissa delmängder (händelser) tolkas som en händelse som består av förekomsten åtminstone ett från dessa händelser. Skärningspunkten (produkten) av delmängder (händelser) tolkas som en händelse som består av förekomsten Allt dessa händelser. Osammanhängande uppsättningar tolkas som oförenlig händelser (deras gemensamma offensiv är omöjlig). Följaktligen betyder den tomma uppsättningen omöjlig händelse.
Sannolikhet ( sannolikhetsmått) kallas mäta(numerisk funktion) definierad på uppsättningen händelser, med följande egenskaper:
Om utrymmet för elementära händelser X säkert, då är det angivna additivitetsvillkoret för godtyckliga två inkompatibla händelser tillräckligt, från vilket additivitet kommer att följa för eventuella slutlig antalet inkompatibla händelser. Men i fallet med ett oändligt (räknebart eller oräkneligt) utrymme av elementära händelser är detta tillstånd inte tillräckligt. Den så kallade räknebar eller sigma-additivitet, det vill säga uppfyllelsen av additivitetsegenskapen för ev inte mer än räkneligt familjer av parvis inkompatibla händelser. Detta är nödvändigt för att säkerställa "kontinuiteten" för sannolikhetsmåttet.
Sannolikhetsmåttet kanske inte definieras för alla delmängder av mängden. Det antas att det är definierat på vissa sigma algebra delmängder . Dessa delmängder kallas mätbar enligt ett givet sannolikhetsmått, och de är slumpmässiga händelser. Mängden - det vill säga mängden elementära händelser, sigma-algebra för dess delmängder och sannolikhetsmåttet - kallas sannolikhetsutrymme.
Kontinuerliga slumpvariabler. Förutom diskreta slumpvariabler, vars möjliga värden bildar en ändlig eller oändlig talföljd som inte helt fyller något intervall, finns det ofta slumpvariabler vars möjliga värden bildar ett visst intervall. Ett exempel på en sådan slumpvariabel är avvikelsen från det nominella värdet av en viss storlek på en del med en korrekt etablerad teknisk process. Denna typ av slumpvariabler kan inte specificeras med hjälp av sannolikhetsfördelningslagen p(x). De kan dock specificeras med hjälp av sannolikhetsfördelningsfunktionen F(x). Denna funktion definieras på exakt samma sätt som i fallet med en diskret slumpvariabel:
![]()
Så även här funktionen F(x) definieras på hela talaxeln och dess värde vid punkten Xär lika med sannolikheten att den slumpmässiga variabeln får ett värde mindre än X. Formel (19) och egenskaperna 1° och 2° är giltiga för fördelningsfunktionen för en slumpvariabel. Beviset utförs på samma sätt som fallet med en diskret kvantitet. Den slumpmässiga variabeln kallas kontinuerlig, om det för den finns en icke-negativ styckvis-kontinuerlig funktion* som uppfyller alla värden x jämlikhet
Baserat på den geometriska betydelsen av integralen som ett område kan vi säga att sannolikheten för att uppfylla ojämlikheterna är lika med arean av en krökt trapets med bas ovanför avgränsad av en kurva (fig. 6).

Sedan och baserat på formel (22)

Observera att för en kontinuerlig slumpvariabel, fördelningsfunktionen F(x) kontinuerlig när som helst X, där funktionen är kontinuerlig. Detta följer av det faktum att F(x)är differentierbar vid dessa punkter. Baserat på formel (23), förutsatt x 1 =x, , vi har
På grund av kontinuiteten i funktionen F(x) det får vi
![]()
Därav
Således, sannolikheten för att en kontinuerlig slumpvariabel kan ta ett enskilt värde på x är noll. Det följer av detta att händelserna som består i uppfyllandet av var och en av ojämlikheterna
De har samma sannolikhet, d.v.s.
Ja, t.ex.
som Kommentar. Som vi vet, om en händelse är omöjlig, är sannolikheten för att den inträffar noll. I den klassiska definitionen av sannolikhet, när antalet testresultat är ändligt, sker också den omvända propositionen: om sannolikheten för en händelse är noll, är händelsen omöjlig, eftersom i detta fall inget av testresultaten gynnar den. I fallet med en kontinuerlig slumpvariabel är antalet möjliga värden oändligt. Sannolikheten att detta värde kommer att anta något särskilt värde x 1 som vi har sett är lika med noll. Därav följer dock inte att denna händelse är omöjlig, eftersom den slumpmässiga variabeln som ett resultat av testet i synnerhet kan anta värdet x 1 . Därför, i fallet med en kontinuerlig slumpvariabel, är det vettigt att tala om sannolikheten att den slumpmässiga variabeln faller in i intervallet, och inte om sannolikheten att den kommer att anta ett visst värde. Så, till exempel, vid tillverkning av en rulle är vi inte intresserade av sannolikheten att dess diameter kommer att vara lika med det nominella värdet. För oss är sannolikheten att rullens diameter inte går utanför toleransen viktig. Exempel. Fördelningstätheten för en kontinuerlig stokastisk variabel ges enligt följande:
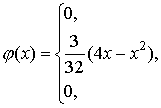

Grafen för funktionen visas i fig. 7. Bestäm sannolikheten för att en stokastisk variabel tar ett värde som uppfyller olikheterna Hitta fördelningsfunktionen för en given stokastisk variabel. ( Beslut)

De följande två styckena ägnas åt fördelningarna av kontinuerliga slumpvariabler som ofta påträffas i praktiken - enhetliga och normala fördelningar.
* En funktion kallas styckvis kontinuerlig på hela den numeriska axeln om den antingen är kontinuerlig på något segment eller har ett ändligt antal diskontinuitetspunkter av det första slaget. ** Regeln för att differentiera en integral med en variabel övre gräns, härledd i fallet med en finit nedre gräns, förblir giltig för integraler med en oändlig nedre gräns. Verkligen,
Sedan integralen
är ett konstant värde.
Beroende och oberoende evenemang. Villkorlig sannolikhet
Skilj mellan beroende och oberoende händelser. Två händelser sägs vara oberoende om förekomsten av en av dem inte ändrar sannolikheten för att den andra inträffar. Till exempel, om två automatiska linjer fungerar i en verkstad, som inte är sammankopplade enligt produktionsförhållandena, är stopp för dessa linjer oberoende händelser.
Exempel 3 Myntet vänds två gånger. Sannolikheten för att "vapenskölden" ska uppträda i det första testet (händelse ) beror inte på utseendet eller avsaknaden av "vapnet" i det andra testet (händelse ). I sin tur beror sannolikheten för utseendet av "vapnet" i det andra testet inte på resultatet av det första testet. Således händelser och oberoende.
Flera evenemang kallas kollektivt oberoende , om någon av dem inte beror på någon annan händelse och på någon kombination av de andra.
Händelserna kallas beroende , om en av dem påverkar sannolikheten att den andra inträffar. Till exempel är två produktionsanläggningar sammankopplade av en enda teknisk cykel. Då beror sannolikheten för misslyckande för en av dem på den andras tillstånd. Sannolikheten för en händelse, beräknad med antagande av att en annan händelse inträffar, kallas betingad sannolikhet händelser och betecknas med .
Villkoret för oberoende av en händelse från en händelse skrivs i formen, och villkoret för dess beroende - i formen. Betrakta ett exempel på att beräkna den villkorade sannolikheten för en händelse.
Exempel 4 Det finns 5 framtänder i kartongen: två slitna och tre nya. Två på varandra följande utdragningar av framtänder görs. Bestäm den villkorade sannolikheten för utseendet av en sliten fräs under den andra extraktionen, förutsatt att fräsen som togs bort för första gången inte återförs till lådan.
Beslut. Låt oss beteckna utvinningen av en sliten fräs i det första fallet, och - utvinningen av en ny. Sedan . Eftersom den borttagna fräsen inte återförs till lådan ändras förhållandet mellan antalet slitna och nya fräsar. Därför beror sannolikheten för att ta bort en sliten fräs i det andra fallet på vilken händelse som ägde rum innan.
Låt oss beteckna den händelse som innebär utdragning av den slitna fräsen i det andra fallet. Sannolikheterna för denna händelse är:
Därför beror sannolikheten för en händelse på om händelsen inträffade eller inte.
Sannolikhetstäthet- ett av sätten att sätta ett sannolikhetsmått på det euklidiska rummet. I det fall då sannolikhetsmåttet är fördelningen av en stokastisk variabel talar man om densitetslumpvariabel.
Sannolikhetstäthet Låta vara ett sannolikhetsmått på, det vill säga ett sannolikhetsutrymme definieras, där betecknar Borel σ-algebra på. Låt beteckna Lebesgue mått på.
Definition 1. Sannolikheten kallas absolut kontinuerlig (med avseende på Lebesgue-måttet) () om någon Borel-uppsättning med noll Lebesgue-mått också har sannolikheten noll:
Om sannolikheten är absolut kontinuerlig, så finns det enligt Radon-Nikodyms sats en icke-negativ Borel-funktion så att
 ,
,
där den vanliga förkortningen används ![]() , och integralen förstås i betydelsen Lebesgue.
, och integralen förstås i betydelsen Lebesgue.
Definition 2. Mer generellt, låt vara ett godtyckligt mätbart utrymme, och låt och vara två mått på detta utrymme. Om det finns en icke-negativ , som gör det möjligt att uttrycka måttet i termer av måttet i formuläret
![]()
då anropas denna funktion mäta densitet som , eller derivat av Radon-Nikodim mäta med avseende på mäta , och beteckna
Om, vid inträffandet av en händelse, sannolikheten för en händelse  inte förändras, då händelserna
inte förändras, då händelserna  och
och  kallad självständig.
kallad självständig.
Sats:Sannolikhet för gemensam förekomst av två oberoende händelser  och
och  (Arbetar
(Arbetar  och
och  ) är lika med produkten av sannolikheterna för dessa händelser.
) är lika med produkten av sannolikheterna för dessa händelser.
Faktiskt, sedan
evenemang  och
och  oberoende alltså
oberoende alltså  . I detta fall formeln för sannolikheten för en produkt av händelser
. I detta fall formeln för sannolikheten för en produkt av händelser  och
och  tar formen.
tar formen.
evenemang  kallad parvis oberoende om två av dem är oberoende.
kallad parvis oberoende om två av dem är oberoende.
evenemang  kallad kollektivt oberoende (eller helt enkelt oberoende), om varannan av dem är oberoende och varje händelse och alla möjliga produkter från de andra är oberoende.
kallad kollektivt oberoende (eller helt enkelt oberoende), om varannan av dem är oberoende och varje händelse och alla möjliga produkter från de andra är oberoende.
Sats:Sannolikhet för produkten av ett ändligt antal oberoende händelser i aggregatet
 är lika med produkten av sannolikheterna för dessa händelser.
är lika med produkten av sannolikheterna för dessa händelser.
Låt oss illustrera skillnaden i tillämpningen av händelsesannolikhetsformlerna för beroende och oberoende händelser med hjälp av exempel
Exempel 1. Sannolikheten att den första skytten träffar målet är 0,85, den andra är 0,8. Vapnen avlossade ett skott i taget. Vad är sannolikheten att minst en projektil träffar målet?
Lösning: P(A+B) =P(A) +P(B) –P(AB) Eftersom skotten är oberoende, då
P(A+B) = P(A) +P(B) –P(A)*P(B) = 0,97
Exempel 2. En urna innehåller 2 röda och 4 svarta kulor. 2 bollar tas ur den i rad. Vad är sannolikheten att båda bollarna är röda.
Lösning: 1 fall. Händelse A - uppkomsten av en röd boll vid den första borttagningen, händelse B - vid den andra. Händelse C är uppkomsten av två röda bollar.
P(C) \u003d P (A) * P (B/A) \u003d (2/6) * (1/5) \u003d 1/15
2:a fallet. Den första bollen som dras återförs till korgen.
P(C) \u003d P (A) * P (B) \u003d (2/6) * (2/6) \u003d 1/9
Total sannolikhetsformel.
Låt evenemanget  kan bara hända med en av de inkompatibla händelserna
kan bara hända med en av de inkompatibla händelserna
 bildar en komplett grupp. Till exempel får butiken samma produkter från tre företag och i olika kvantiteter. Sannolikheten för att producera lågkvalitativa produkter på dessa företag är olika. En av produkterna är slumpmässigt utvalda. Det är nödvändigt att fastställa sannolikheten för att denna produkt är av dålig kvalitet (händelse
bildar en komplett grupp. Till exempel får butiken samma produkter från tre företag och i olika kvantiteter. Sannolikheten för att producera lågkvalitativa produkter på dessa företag är olika. En av produkterna är slumpmässigt utvalda. Det är nödvändigt att fastställa sannolikheten för att denna produkt är av dålig kvalitet (händelse  ). Händelser här
). Händelser här
 - detta är valet av en produkt från produkterna från motsvarande företag.
- detta är valet av en produkt från produkterna från motsvarande företag.
I det här fallet, sannolikheten för händelsen  kan betraktas som summan av produkter av händelser
kan betraktas som summan av produkter av händelser  .
.
Genom additionssatsen för sannolikheterna för oförenliga händelser får vi  . Med hjälp av sfinner vi
. Med hjälp av sfinner vi
 .
.
Den resulterande formeln kallas formel för total sannolikhet.
Bayes formel
Låt evenemanget  sker samtidigt som en av
sker samtidigt som en av  oförenliga händelser
oförenliga händelser
 , vars sannolikheter
, vars sannolikheter  (
( ) är kända innan erfarenhet ( a priori sannolikheter). Ett experiment utförs, som ett resultat av vilket inträffandet av en händelse registreras
) är kända innan erfarenhet ( a priori sannolikheter). Ett experiment utförs, som ett resultat av vilket inträffandet av en händelse registreras  , och det är känt att denna händelse hade vissa villkorade sannolikheter
, och det är känt att denna händelse hade vissa villkorade sannolikheter  (
( ). Det krävs för att hitta sannolikheterna för händelser
). Det krävs för att hitta sannolikheterna för händelser  om händelsen är känd
om händelsen är känd  hände ( a posteriori sannolikheter).
hände ( a posteriori sannolikheter).
Problemet är att, med ny information (händelse A har inträffat), är det nödvändigt att överskatta sannolikheterna för händelser
 .
.
Baserat på satsen om sannolikheten för produkten av två händelser

 .
.
Den resulterande formeln kallas Bayes formler.
Grundläggande begrepp inom kombinatorik.
När man löser ett antal teoretiska och praktiska problem krävs det att man gör olika kombinationer av en ändlig uppsättning element enligt givna regler och att man räknar antalet av alla möjliga sådana kombinationer. Sådana uppgifter kallas kombinatoriskt.
När man löser problem använder kombinatoriken reglerna för summa och produkt.
När man bedömer sannolikheten för att någon slumpmässig händelse inträffar är det mycket viktigt att ha en god uppfattning i förväg om sannolikheten (sannolikheten för händelsen) för att händelsen av intresse för oss ska inträffa beror på hur andra händelser utvecklas. När det gäller det klassiska schemat, när alla utfall är lika sannolika, kan vi redan på egen hand uppskatta sannolikhetsvärdena för den individuella händelsen av intresse för oss. Vi kan göra detta även om evenemanget är en komplex samling av flera elementära resultat. Och om flera slumpmässiga händelser inträffar samtidigt eller i följd? Hur påverkar detta sannolikheten för händelsen av intresse för oss? Om jag slår en tärning några gånger och vill få en sexa och jag inte har tur hela tiden, betyder det att jag ska öka min insats eftersom jag, enligt sannolikhetsteorin, är på väg att ha tur? Tyvärr säger sannolikhetsteorin inget sådant. Varken tärningar, kort eller mynt kan komma ihåg vad de visade oss förra gången. Det spelar ingen roll för dem om jag för första gången eller för tionde gången idag testar mitt öde. Varje gång jag rullar igen vet jag bara en sak: och den här gången är sannolikheten att rulla en "sexa" igen en sjättedel. Det betyder förstås inte att numret jag behöver aldrig kommer att falla ut. Det betyder bara att min förlust efter den första kastningen och efter alla andra kast är oberoende händelser. Händelser A och B kallas oberoende om förverkligandet av en av dem inte påverkar sannolikheten för den andra händelsen på något sätt. Till exempel beror sannolikheten för att träffa ett mål med den första av två pistoler inte på om den andra pistolen träffade målet, så händelserna "den första pistolen träffade målet" och "den andra pistolen träffade målet" är oberoende. Om två händelser A och B är oberoende, och sannolikheten för var och en av dem är känd, kan sannolikheten för att både händelse A och händelse B inträffar samtidigt (betecknas med AB) beräknas med följande teorem.
Sannolikhetsmultiplikationssats för oberoende händelser
P(AB) = P(A)*P(B) sannolikheten för att två oberoende händelser ska inträffa samtidigt är lika med produkten av sannolikheterna för dessa händelser.
Exempel 1. Sannolikheten för att träffa målet när den första och andra pistolen avfyras är lika: p 1 = 0,7; p2 = 0,8. Hitta sannolikheten att slå med en volley med båda pistolerna samtidigt.
Som vi redan har sett är händelserna A (träff av den första pistolen) och B (träffen av den andra pistolen) oberoende, d.v.s. P(AB)=P(A)*P(B)=pl*p2=0,56. Vad händer med våra uppskattningar om de initierande händelserna inte är oberoende? Låt oss ändra det tidigare exemplet lite.
Exempel 2 Två skyttar i en tävling skjuter på mål, och om en av dem skjuter korrekt, börjar motståndaren bli nervös och hans resultat förvärras. Hur kan man vända denna vardagliga situation till ett matematiskt problem och skissera sätt att lösa det? Det är intuitivt tydligt att det är nödvändigt att på något sätt separera de två scenarierna, att i själva verket komponera två scenarier, två olika uppgifter. I det första fallet, om motståndaren missar, kommer scenariot att vara gynnsamt för den nervösa idrottaren och hans noggrannhet blir högre. I det andra fallet, om motståndaren anständigt insåg sin chans, minskar sannolikheten att träffa målet för den andra idrottaren. För att skilja de möjliga scenarierna (de kallas ofta hypoteser) för utvecklingen av händelser kommer vi ofta att använda "sannolikhetsträdet". Det här diagrammet liknar i betydelse beslutsträdet, som du förmodligen redan har haft att göra med. Varje gren är ett separat scenario, bara nu har det sitt eget värde på den så kallade villkorade sannolikheten (q 1 , q 2 , q 1 -1, q 2 -1).
Detta schema är mycket bekvämt för analys av successiva slumpmässiga händelser. Det återstår att klargöra ytterligare en viktig fråga: var kommer de initiala sannolikhetsvärdena ifrån i verkliga situationer? Sannolikhetsteorin fungerar trots allt inte med samma mynt och tärningar, eller hur? Vanligtvis är dessa uppskattningar hämtade från statistik, och när statistik inte finns tillgänglig gör vi vår egen forskning. Och vi måste ofta börja det inte med att samla in data, utan med frågan om vilken information vi generellt behöver.
Exempel 3 I en stad med 100 000 invånare, anta att vi behöver uppskatta storleken på marknaden för en ny icke-nödvändig produkt, till exempel ett färgbehandlat hårbalsam. Låt oss överväga "sannolikhetsträdet" -schemat. I det här fallet måste vi ungefär uppskatta värdet av sannolikheten på varje "gren". Så våra uppskattningar av marknadskapacitet:
1) 50 % av alla invånare i staden är kvinnor,
2) av alla kvinnor färgar bara 30 % håret ofta,
3) av dessa använder endast 10 % balsam för färgat hår,
4) av dessa kan bara 10 % ta mod till sig att prova en ny produkt,
5) 70 % av dem köper vanligtvis inte allt från oss, utan från våra konkurrenter.

Enligt lagen om multiplikation av sannolikheter bestämmer vi sannolikheten för händelsen av intresse för oss A \u003d (en stadsbor köper denna nya balsam från oss) \u003d 0,00045. Multiplicera detta sannolikhetsvärde med antalet invånare i staden. Som ett resultat har vi bara 45 potentiella köpare, och med tanke på att en flaska med denna produkt räcker i flera månader är handeln inte särskilt livlig. Ändå finns det fördelar med våra bedömningar. För det första kan vi jämföra prognoserna för olika affärsidéer, de kommer att ha olika "gafflar" på diagrammen, och naturligtvis kommer sannolikhetsvärdena också att vara olika. För det andra, som vi redan har sagt, kallas en slumpvariabel inte slumpmässig eftersom den inte beror på någonting alls. Det är bara det att dess exakta innebörd inte är känd i förväg. Vi vet att det genomsnittliga antalet köpare kan ökas (till exempel genom att annonsera en ny produkt). Så det är vettigt att fokusera på de där "gafflarna" där fördelningen av sannolikheter inte passar oss särskilt, på de faktorer som vi kan påverka. Betrakta ett annat kvantitativt exempel på forskning om konsumentbeteende.
Exempel 3 I genomsnitt besöker 10 000 personer matmarknaden per dag. Sannolikheten att en marknadsbesökare går in i en mejeripaviljong är 1/2. Det är känt att i denna paviljong säljs i genomsnitt 500 kg olika produkter per dag. Kan man hävda att medelköpet i paviljongen bara väger 100 g?
Diskussion.
Självklart inte. Det är tydligt att inte alla som gick in i paviljongen hamnade i att köpa något där.

Som visas i diagrammet, för att kunna svara på frågan om den genomsnittliga inköpsvikten, måste vi hitta svaret på frågan, vad är sannolikheten att en person som går in i paviljongen köper något där. Om vi inte har sådana uppgifter till vårt förfogande, men vi behöver dem, måste vi skaffa dem själva efter att ha observerat besökarna i paviljongen under en tid. Anta att våra observationer visar att endast en femtedel av besökarna i paviljongen köper något. Så snart dessa uppskattningar erhålls av oss, blir uppgiften redan enkel. Av de 10 000 personer som kom till marknaden kommer 5 000 att gå till paviljongen med mejeriprodukter, det blir bara 1 000 inköp.Den genomsnittliga köpvikten är 500 gram. Det är intressant att notera att för att bygga en fullständig bild av vad som händer, måste logiken med villkorad "förgrening" definieras i varje skede av vårt resonemang lika tydligt som om vi arbetade med en "konkret" situation, och inte med sannolikheter.
Uppgifter för självrannsakan.
1. Låt det finnas en elektrisk krets som består av n seriekopplade element, som vart och ett fungerar oberoende av de andra. Sannolikheten p för att varje element inte ska misslyckas är känd. Bestäm sannolikheten för korrekt funktion av hela sektionen av kretsen (händelse A).

2. Studenten kan 20 av de 25 tentamensfrågorna. Hitta sannolikheten att studenten kan de tre frågorna som examinatorn ställt till honom.
3. Produktionen består av fyra på varandra följande steg, som var och en driver utrustning för vilken sannolikheten för fel under nästa månad är p 1 , p 2 , p 3 respektive p 4 . Hitta sannolikheten att det om en månad inte kommer att bli något produktionsstopp på grund av utrustningsfel.
Händelsernas beroende förstås i probabilistisk mening, inte funktionellt. Detta innebär att utseendet av en av de beroende händelserna inte entydigt kan bedöma utseendet på den andra. Sannolikhetsberoende innebär att förekomsten av en av de beroende händelserna endast ändrar sannolikheten för att den andra ska inträffa. Om sannolikheten inte ändras anses händelserna vara oberoende.
Definition: Låt - godtyckligt sannolikhetsutrymme, - några slumpmässiga händelser. Det säger de händelse MEN beror inte på händelsen PÅ , om dess villkorade sannolikhet är densamma som dess ovillkorliga sannolikhet:
![]() .
.
Om en ![]() , då säger vi att händelsen MEN händelseberoende PÅ.
, då säger vi att händelsen MEN händelseberoende PÅ.
Begreppet oberoende är symmetriskt, det vill säga om en händelse MEN beror inte på händelsen PÅ, sedan händelsen PÅ beror inte på händelsen MEN. Verkligen, låt ![]() . Sedan
. Sedan  . Därför säger de helt enkelt att händelserna MEN och PÅ självständig.
. Därför säger de helt enkelt att händelserna MEN och PÅ självständig.
Följande symmetriska definition av händelsernas oberoende följer av regeln om multiplikation av sannolikheter.
Definition: Evenemang MEN och PÅ, definierade på samma sannolikhetsutrymme kallas självständig, om
Om en , sedan händelserna MEN och PÅ kallad beroende.
Observera att denna definition också är giltig när eller .
Egenskaper för oberoende evenemang.
1. Om händelser MEN och PÅär oberoende, då är följande händelsepar också oberoende: .
▲ Låt oss till exempel bevisa händelsernas oberoende . Föreställ dig en händelse MEN som: . Eftersom händelserna är oförenliga, alltså , och på grund av händelsernas oberoende MEN och PÅ det får vi. Alltså, vilket betyder oberoende. ■
2. Om händelsen MEN beror inte på händelser I 1 och I 2, som är inkompatibla () , den händelsen MEN beror inte på mängden.
▲ Faktum är att använda axiomet för additivitet för sannolikhet och oberoende av händelsen MEN från händelser I 1 och I 2, vi har:
Samband mellan begreppen oberoende och oförenlighet.
Låt vara MEN och PÅ- alla händelser som har en sannolikhet som inte är noll: , så ![]() . Om händelserna MEN och PÅär inkonsekventa (), och därför kan jämlikhet aldrig ske. Således, oförenliga händelser är beroende.
. Om händelserna MEN och PÅär inkonsekventa (), och därför kan jämlikhet aldrig ske. Således, oförenliga händelser är beroende.
När mer än två händelser betraktas samtidigt, karaktäriserar deras parvisa oberoende inte tillräckligt sambandet mellan händelserna i hela gruppen. I detta fall introduceras begreppet oberoende i aggregatet.
Definition: Händelser definierade på samma sannolikhetsutrymme kallas kollektivt oberoende, om för någon 2 £m £n och varje kombination av index håller jämställdheten:
På m = 2 Oberoende i aggregatet innebär parvis oberoende av händelser. Det omvända är inte sant.
Exempel. (Bernstein S.N.)
Ett slumpmässigt experiment består i att kasta en vanlig tetraeder (tetraeder). Det finns ett ansikte som har fallit ut uppifrån och ner. Tetraederns ytor är färgade enligt följande: 1:a ansiktet - vit, 2:a ansiktet - svart,
3 ansikte - rött, 4 ansikte - innehåller alla färger.
Tänk på händelserna:
MEN= (Avfall av vit färg); B= (Black drop out);
C= (Rött bortfall).
Sedan ![]() ;
;
Därför händelserna MEN, PÅ och Medär parvis oberoende.
Dock, ![]() .
.
Därför händelser MEN, PÅ och Med tillsammans är de inte oberoende.
I praktiken, som regel, fastställs inte händelsernas oberoende genom att kontrollera det per definition, utan vice versa: händelser anses vara oberoende av vissa yttre överväganden eller med hänsyn till omständigheterna i ett slumpmässigt experiment, och oberoende används för att hitta sannolikheter för att producera händelser.
Sats (multiplikationer av sannolikheter för oberoende händelser).
Om händelser definierade på samma sannolikhetsutrymme är oberoende i aggregatet, är sannolikheten för deras produkt lika med produkten av sannolikheterna:
▲ Beviset för satsen följer av definitionen av händelsernas oberoende i aggregatet eller från den allmännan, med hänsyn till det faktum att i detta fall
Exempel 1 (typiskt exempel för att hitta betingade sannolikheter, begreppet oberoende, sannolikhetsadditionssatsen).
Den elektriska kretsen består av tre oberoende verksamma element. Felsannolikheterna för vart och ett av elementen är lika med .
 1) Hitta sannolikheten för kretsfel.
1) Hitta sannolikheten för kretsfel.
2) Kretsen är känd för att ha misslyckats.
Vad är sannolikheten att det misslyckas:
a) 1:a elementet; b) 3:e elementet?
Beslut.Överväg händelser = (misslyckades k element) och händelsen MEN= (Schema misslyckades). Sedan händelsen MEN presenteras i formen:
![]() .
.
1) Eftersom händelserna och inte är oförenliga, så är sannolikhetsaxiomet för sannolikhet P3) inte tillämpligt och för att hitta sannolikheten bör man använda den allmänna sannolikhetsadditionssatsen, enligt vilken
Relaterade publikationer
-
 Walking Dead: The Final Season walkthrough När kommer det andra avsnittet av walking dead ut
Walking Dead: The Final Season walkthrough När kommer det andra avsnittet av walking dead ut
I den här genomgången övervägs endast ett av alternativen för att klara spelet! + Beskrev att hitta alla samlarföremål. Avsnitt 1:...
-
 Passage av handlingen Truckers 3 spelets hemligheter
Passage av handlingen Truckers 3 spelets hemligheter
Tredje livet bakom ratten, Tre århundraden utan sömn. "Du är inte ensam", grupp DDT Rassvet. Några hundra mil bakom, rosa berg framför, och bakom dem...